
Large language models (LLMs) have become increasingly popular due to their ability to process, generate, and manipulate texts in multiple human languages. However, as these models improve in generating convincing texts that resemble human writing, they are also prone to hallucinations. Hallucinations in this context refer to LLMs generating inaccurate, nonsensical, or inappropriate responses.
Researchers at DeepMind have recently developed a new procedure to tackle this issue. Their approach involves using LLMs to evaluate their own responses and determine the similarity between each sampled response for a given query. By leveraging conformal prediction techniques, the team aims to develop an abstention procedure that can identify instances where LLMs should refrain from responding, thus reducing the likelihood of hallucinations.
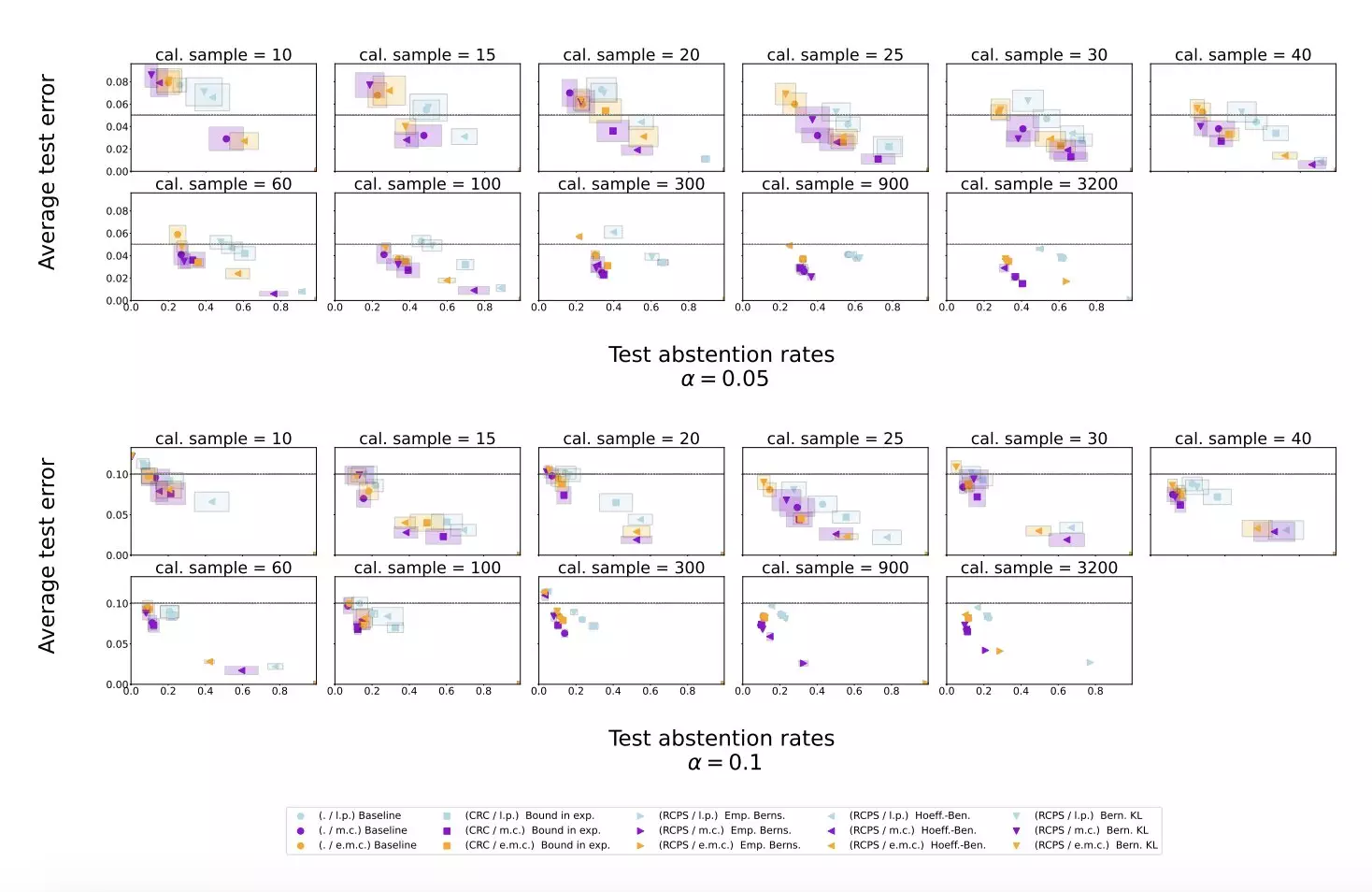
In a series of experiments using publicly available datasets containing queries and responses, the research team evaluated their proposed method on Gemini Pro, an LLM developed by Google. The results showed that the conformal abstention method effectively mitigated hallucinations on generative question answering datasets. This approach also maintained a less conservative abstention rate on datasets with long responses compared to baseline methods, while achieving comparable performance on datasets with short answers.
The findings of this study suggest that the proposed conformal calibration and similarity scoring procedure can significantly reduce LLM hallucinations. By allowing the model to abstain from providing inaccurate or nonsensical responses, this approach outperforms traditional scoring procedures. The success of this method could lead to the development of similar techniques to enhance the reliability of LLMs and prevent hallucinations in the future.
Overall, the research carried out by DeepMind demonstrates the importance of addressing the issue of hallucinations in large language models. By implementing effective mitigation strategies, such as the conformal abstention method, researchers can enhance the performance and trustworthiness of LLMs, making them more reliable for widespread use among professionals worldwide. This study opens up new avenues for improving the quality of text generated by artificial neural networks and underscores the importance of ongoing research in this field.